
做小红书内容运营的人,都有一个共同的痛点:素材整理太费时间。
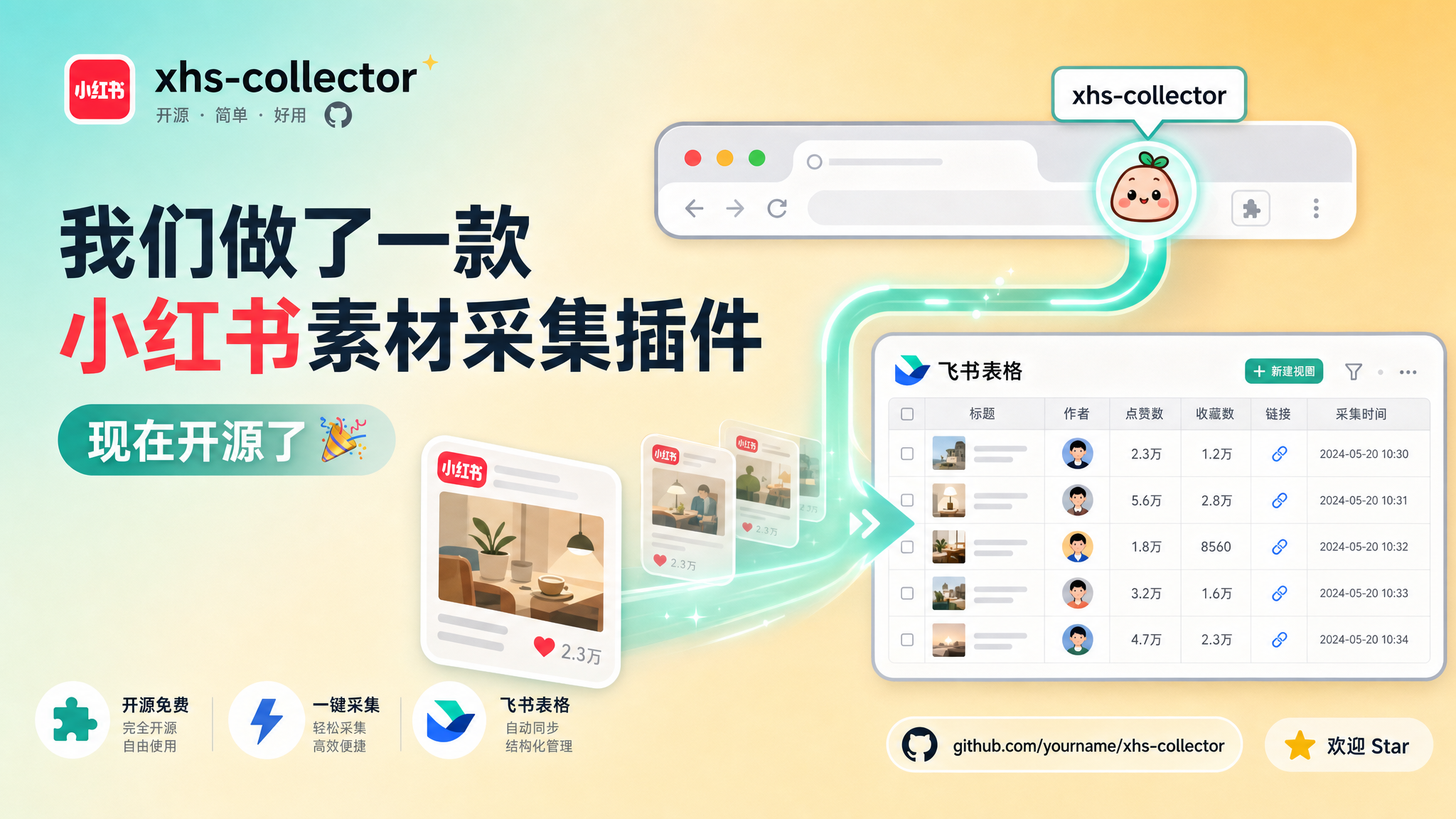
▲ xhs-collector:在浏览器里点一下,笔记自动进飞书
笔记要归类、图片要存档、链接要记录、互动数据要统计。一个人做还好,团队一旦超过 3 个人,靠复制粘贴往表格里填,每天至少浪费半小时。
所以我们做了 xhs-collector。

▲ 运营人的日常:复制 → 粘贴 → 切窗口 → 重来
它能干什么

▲ 一键采集,覆盖笔记的 6 个核心字段
采集的内容包括:
- 📝 笔记标题
- 👤 作者信息
- 📄 正文内容
- 🖼️ 图片链接
- 📊 点赞、收藏、评论数据
- 🕐 发布时间
不需要手动复制粘贴,不需要来回切窗口。打开小红书网页版,看到有价值的笔记,点一下按钮,数据就进飞书了。
为什么做这个
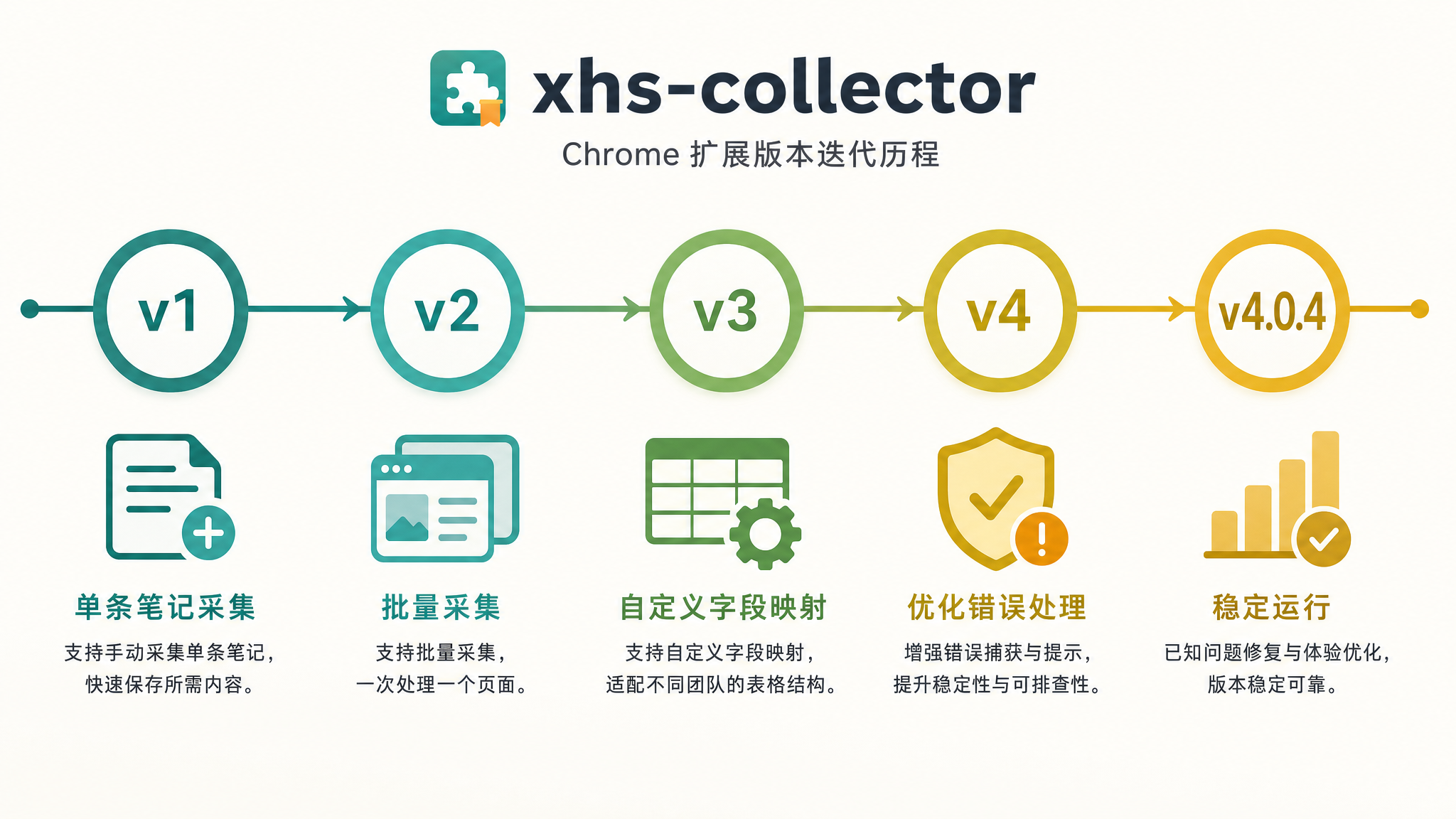
▲ 从自己用到团队用,5 个大版本的迭代之路
最早是我自己用。团队在飞书多维表格里管理内容素材,每天要从小红书搬几十条笔记。搬烦了,找 AI 帮我写了段代码,做了一个很简陋的版本。
后来同事问能不能给他们也装上,我才开始认真做这件事。从 v1 到 v4,迭代了 5 个大版本:
v1 最基础的单条采集 — 先跑起来再说
v2 加了批量采集 — 一次能抓一页,效率翻倍
v3 支持自定义字段映射 — 不同团队的表格结构不一样
v4 完善了错误处理 — 不用再担心采一半报错
v4.0.4 最新稳定版 — 团队内部持续运行中
技术方案
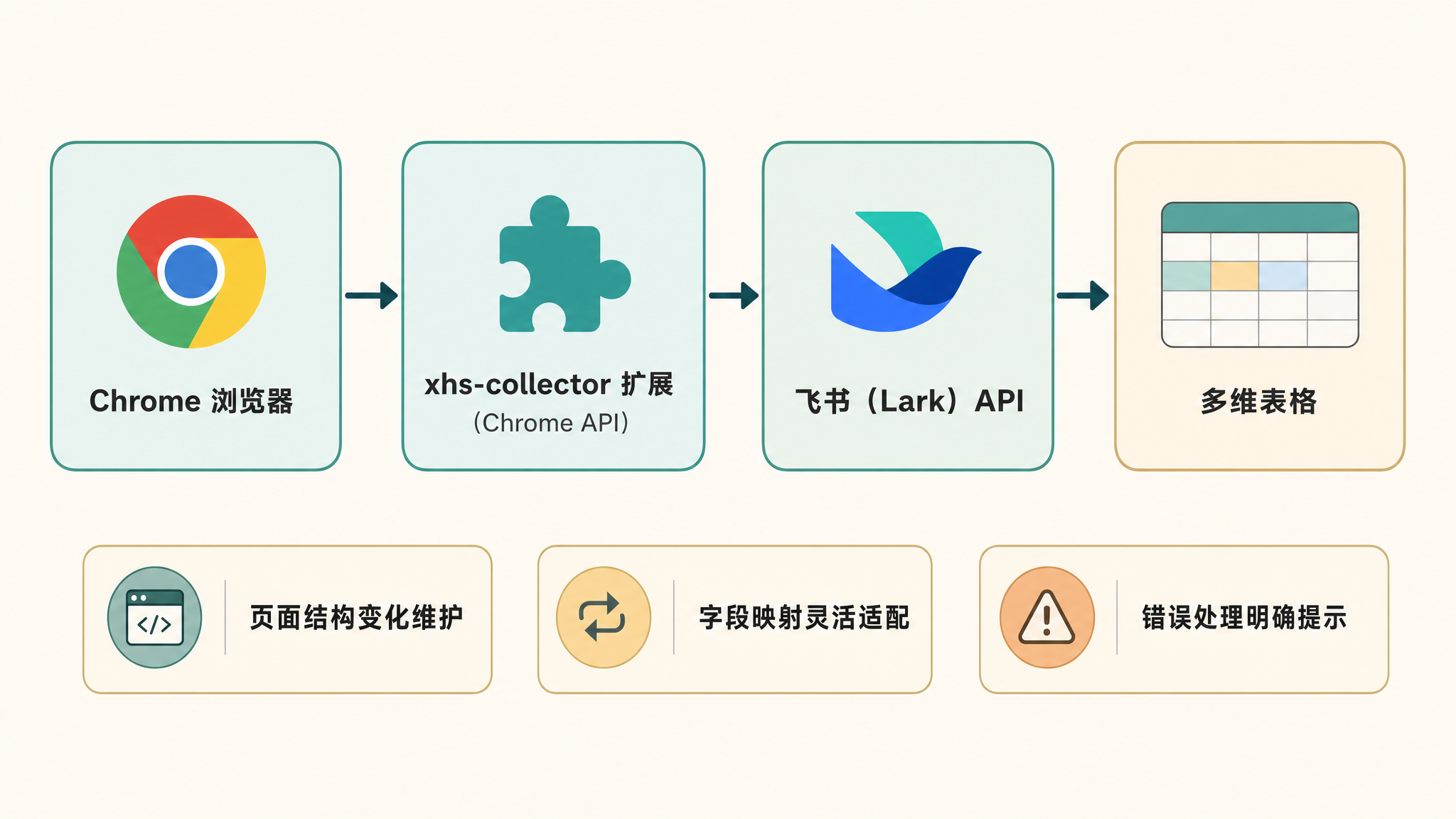
▲ 浏览器扩展 + 飞书 API,简单但实用
插件本身是 Chrome 浏览器扩展,前端在网页里提取数据,后端通过飞书 API 写入多维表格。
核心逻辑不复杂,但有几个细节花了最多时间:
1 小红书页面结构经常变 — 前端选择器要持续维护,每次小红书改版都要跟
2 飞书多维表格的字段映射 — 不同团队用不同表结构,要做到灵活适配
3 错误处理 — 网络断了、token 过期了、表结构改了——都要给用户明确的提示,而不是静默失败
这些细节,才是一个工具从"能用"到"好用"的距离。
开源了

▲ 开源在 GitHub,安装说明都在 README 里
我们把 xhs-collector 开源在了 GitHub:
如果你有内容团队或运营团队,日常需要采集小红书素材并同步到飞书,可以试试这款插件。
后续计划
目前 xhs-collector 已经在我们团队内部稳定运行了几个月。后续计划:
如果你在使用中遇到任何问题,或者有功能建议,欢迎在 GitHub 提 Issue。也欢迎 PR 贡献。
想参与内部测试的,评论区留言,我来联系你 👋